

Pythonで株価を取得してみたいと思い、
「Webスクレーピング」に挑戦しようとしたものの、
- XPathって何?
- HTML構造がよく分からない
- サンプルコードは動くけど意味が分からない
と感じた方も多いのではないでしょうか。私自身、普段は電子工作で
C/C++ や MicroPython を書くことが多く、
Webスクレーピングはほぼ初体験でした。
しかし実際にやってみると、
「HTMLの構造さえ分かれば、スクレーピングはほぼ完成」
ということに気づきました。
この記事では、Pythonの Selenium を使って
ヤフーファイナンスから株価(始値・高値・安値・終値など)を取得する方法 を、
- Selenium 4 の基本的な使い方
- ヤフーファイナンスの HTML 構造(dt / dd)
- 初心者でも理解しやすいデータの取り方
という視点で、やさしく解説していきます。
なぜ Selenium を使うのか
ヤフーファイナンスは JavaScript で動的に描画される
Selenium vs BeautifulSoup
| 項目 | Selenium | BeautifulSoup |
|---|---|---|
| JavaScript | ◎ | ✕ |
| 動的ページ | ◎ | ✕ |
| 速度 | △ | ◎ |
| 学習コスト | 高め | 低め |
| Yahoo Finance | ◎ | ほぼ不可 |
👉 Yahoo ファイナンスは Selenium 一択
今回取得したい株価データ
例(トヨタ自動車など):
前日終値
始値
高値
安値
出来高
売買代金
👉 表示されている情報をそのまま取得するのが目的
ヤフーファイナンスのHTML構造を見てみる
開発者ツールで確認すると、
株価情報は以下のような構造になっています。
実際にクロームで表示させてみた画面です
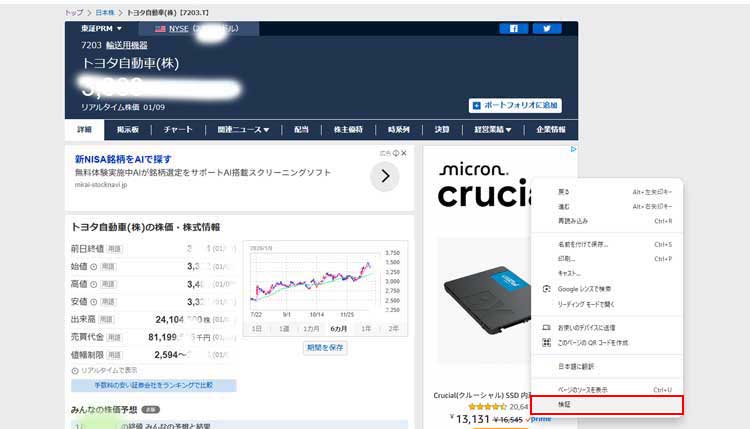
検証をクリック
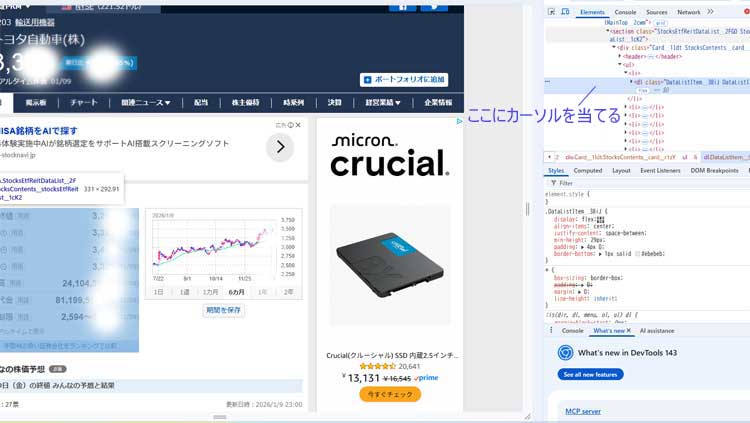
カーソルを当ててブルーに変化したところが今回取りたい部分のデータですね
今回XPathでセレニウムに要素の取得をさせましたが、他にもCSS IDなどの方法もあります興味のある方はぜひ自分で調べてください。
XPathを取得します。
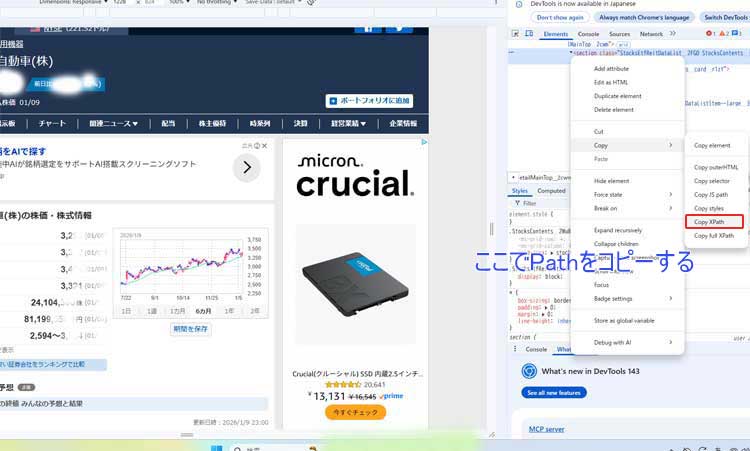
XPathは「取れる」より「絞る」が重要
開発者ツールで確認する
//*[@id="detail"]/section[1]でも要素は取得できます。
しかし実際には、
この section の中には 株価情報以外の要素 も含まれています。
そこで、さらに一段下の div を指定します。
//*[@id="detail"]/section[1]/divこうすることで、
- 株価情報だけを含むブロックに限定できる
- 余計な要素を処理しなくて済む
- HTML構造が多少変わっても壊れにくい
というメリットがあります。
XPathは「一番短いもの」ではなく、
「意味的に一番狭いもの」を選ぶのがコツです。
またパスの中に””の要素が含まれているのも注意しましょう
container_xpath = ‘//*[@id=”detail”]/section[1]/div’このようにシングルコートで囲まないとエラーになります。
こちらの部分を詳しく理解することが、ウェブスクレーピングの上達には欠かせないようで、またHTMLやJavaScriptなどの知識も必要となります。
サンプルプログラム
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# --- エラー対策:ブラウザの設定 ---
options = Options()
# options.add_argument('--headless') # 画面を表示させたくない場合はコメントアウトを外す
driver = webdriver.Chrome(options=options)
try:
driver.get("https://finance.yahoo.co.jp/quote/7203.T")
time.sleep(2) #動きを確認するために画面の表示をしています
# 構造を正しく辿るロジック ---
wait = WebDriverWait(driver, 10) #明示的待機 動的サイトにはこちらの命令を使いましょう
# 1. まず、株価詳細が並んでいる「大きな箱(div)」を指定する
# ※ここは先ほど検証したように、構造的に安定した場所を選びます
#要素の取得はID CSSでなく今回はXPathにしました動的サイトですので
container_xpath = '//*[@id="detail"]/section[1]/div'
#container = driver.find_element(By.XPATH, container_xpath)
# containerを見つける際にも、しっかり「待機」の恩恵を受ける
container = wait.until(EC.presence_of_element_located((By.XPATH, container_xpath)))
# 2. その箱の中にある「各項目の塊(li)」をすべてリストアップする
items = container.find_elements(By.TAG_NAME, "li")
stock_data = {}
# 3. 各項目の塊(li)を一つずつ解析する
for item in items:
try:
# liタグの中から、項目名(dt)と値(dd)を相対的に抽出
# この「item.」から始めるのが、その箱の中だけを探すポイント!
label = item.find_element(By.TAG_NAME, "dt").text
value = item.find_element(By.TAG_NAME, "dd").text
# 不要な「用語」という文字を削除
label = label.replace("用語", "").strip()
stock_data[label] = value
except:
# dtやddがない要素(広告など)はスキップ
continue
# 一括表示
print(stock_data)
#見やすく整形して表示します
for k ,v in stock_data.items():
v = v.replace("\n", " ").strip()
print(k,v)
finally:
driver.quit() #ドライバーを終了しますプログラムの詳しい説明はプログラムの中のコメントに表記しておいたのでそれを参考にしてください。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECpipでインストールが必要なのは「selenium」だけです
pip install selenium上記のプログラムの実行結果です
一部消しゴムで消しております

サンプルプログラム2
見栄えが良く出力するようにし、銘柄名を追加すれば複数の銘柄が自動的に取れるよう改造しました。
次回はエクセルなどに出力してデータを可視化するようにしたいと思います。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
# --- 1. ブラウザの起動設定 ---
options = Options()
# options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
# 取得したい銘柄コードのリスト
codes = ["7203", "3382"] # トヨタ, セブン&アイ
try:
for code in codes:
# --- 2. 目的のページを開く ---
url = f"https://finance.yahoo.co.jp/quote/{code}.T"
driver.get(url)
time.sleep(3) # 読み込み待ち
# --- 3. 銘柄名を取得する ---
# ページの最上部にある銘柄名(h1タグなど)を取得
# Yahooファイナンスの銘柄名は現在 <h1> 属性にあります
stock_name = driver.find_element(By.TAG_NAME, "h1").text
# --- 4. データの取得 ---
items_xpath = "//section[contains(., '前日終値')]//dl"
items = driver.find_elements(By.XPATH, items_xpath)
stock_data = {"銘柄名": stock_name} # 最初に銘柄名を入れておく
for item in items:
try:
label = item.find_element(By.TAG_NAME, "dt").text
value = item.find_element(By.TAG_NAME, "dd").text
label = label.replace("用語", "").strip()
stock_data[label] = value
except:
continue
# --- 5. 結果の表示 ---
print(f"\n=== {stock_name} ({code}) のデータ ===")
for key, val in stock_data.items():
if key == "銘柄名": continue # 銘柄名は既に出したので飛ばす
clean_val = val.replace('\n', ' ')
print(f"{key}: {clean_val}")
print("-" * 30)
finally:
driver.quit()スクレーピングを行う際の注意点
Webスクレーピングはとても便利な技術ですが、
使い方を間違えるとトラブルの原因になることもあります。
以下の点には必ず注意しましょう。
アクセス頻度は控えめにする
短時間に何度もリクエストを送ると、
サーバーに大きな負荷をかけてしまいます。
そのためtime.sleep() などで処理の間隔をあける
定期実行する場合も回数を最小限にする
といった配慮が必要です。
利用規約を必ず確認する
Webサイトには利用規約(Terms of Service)があり、
スクレーピングを禁止している場合もあります。
特に、
商用利用
データの再配布
大量取得
を行う場合は、
事前に利用規約を確認することが重要です。
まとめ
今回は、PythonのSeleniumを使って
ヤフーファイナンスから株価情報を取得する方法を紹介しました。
単にXPathをコピーするのではなく、
- 開発者ツールでHTML構造を確認する
- dt / dd という情報のまとまりを意識する
- section や div を使って意味のある範囲に絞る
といった考え方を理解することで、
より安定したスクレーピングが可能になります。
ヤフーファイナンスのような動的サイトでは、
「始値」「高値」といった文字列を直接探すよりも、
HTML構造からデータを取り出す発想が重要です。
データが取得できてしまえば、
あとは Python の辞書や pandas を使って
CSV や Excel に出力するのも簡単です。
スクレーピングは少し難しそうに見えますが、
構造を理解して一歩ずつ進めれば、
プログラミングの視野を大きく広げてくれる技術です。
ぜひ、今回のサンプルを元に
自分なりの取得方法を試してみてください。

